publications
Please refer to my Google Scholar for a complete publication list.
2025
- ArXiv
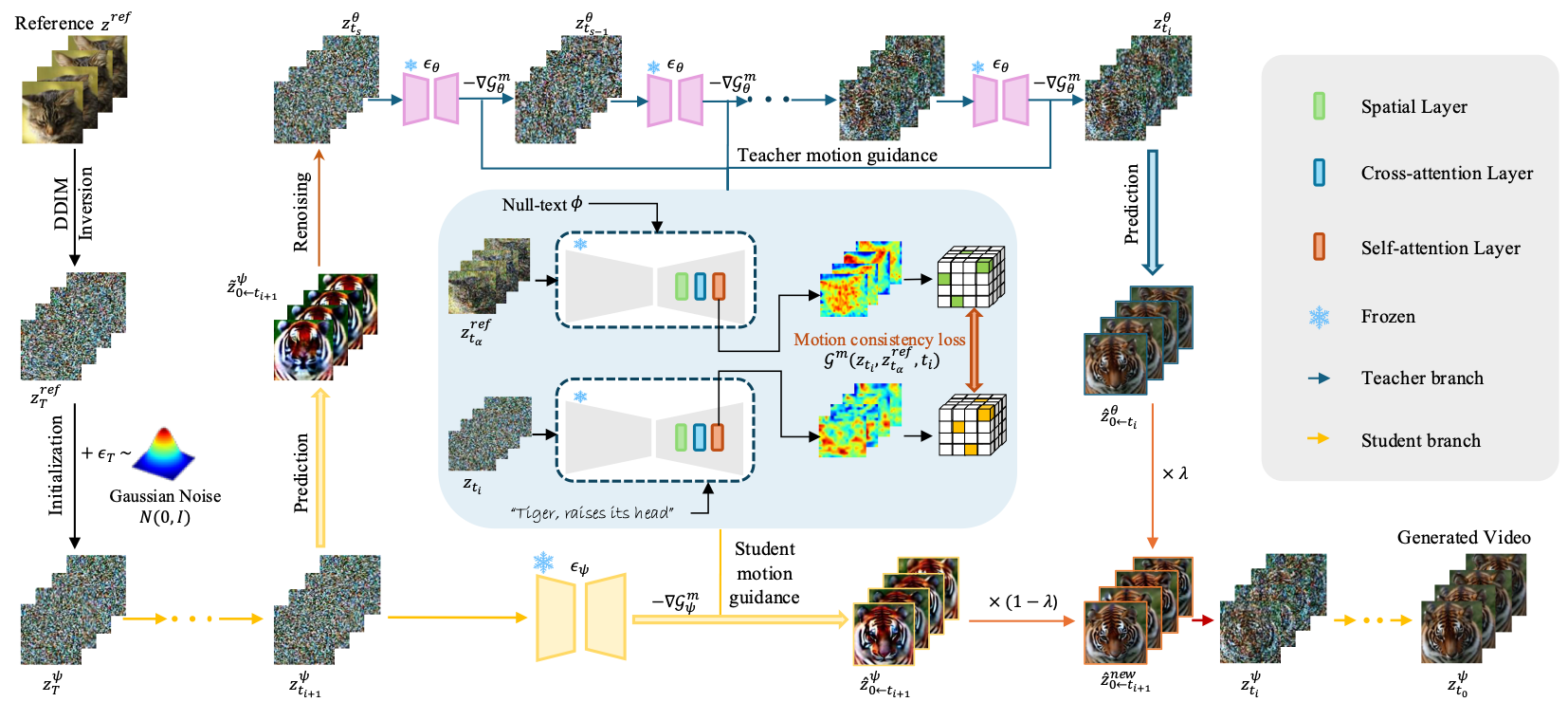 Training-Free Motion Customization for Distilled Video Generators with Adaptive Test-Time DistillationJintao Rong, Xin Xie, Xinyi Yu, and 4 more authorsIn ArXiv Preprint, 2025
Training-Free Motion Customization for Distilled Video Generators with Adaptive Test-Time DistillationJintao Rong, Xin Xie, Xinyi Yu, and 4 more authorsIn ArXiv Preprint, 2025Distilled video generation models offer fast and efficient synthesis but struggle with motion customization when guided by reference videos, especially under training-free settings. Existing training-free methods, originally designed for standard diffusion models, fail to generalize due to the accelerated generative process and large denoising steps in distilled models. To address this, we propose MotionEcho, a novel training-free test-time distillation framework that enables motion customization by leveraging diffusion teacher forcing. Our approach uses high-quality, slow teacher models to guide the inference of fast student models through endpoint prediction and interpolation. To maintain efficiency, we dynamically allocate computation across timesteps according to guidance needs. Extensive experiments across various distilled video generation models and benchmark datasets demonstrate that our method significantly improves motion fidelity and generation quality while preserving high efficiency.
- IJCAI
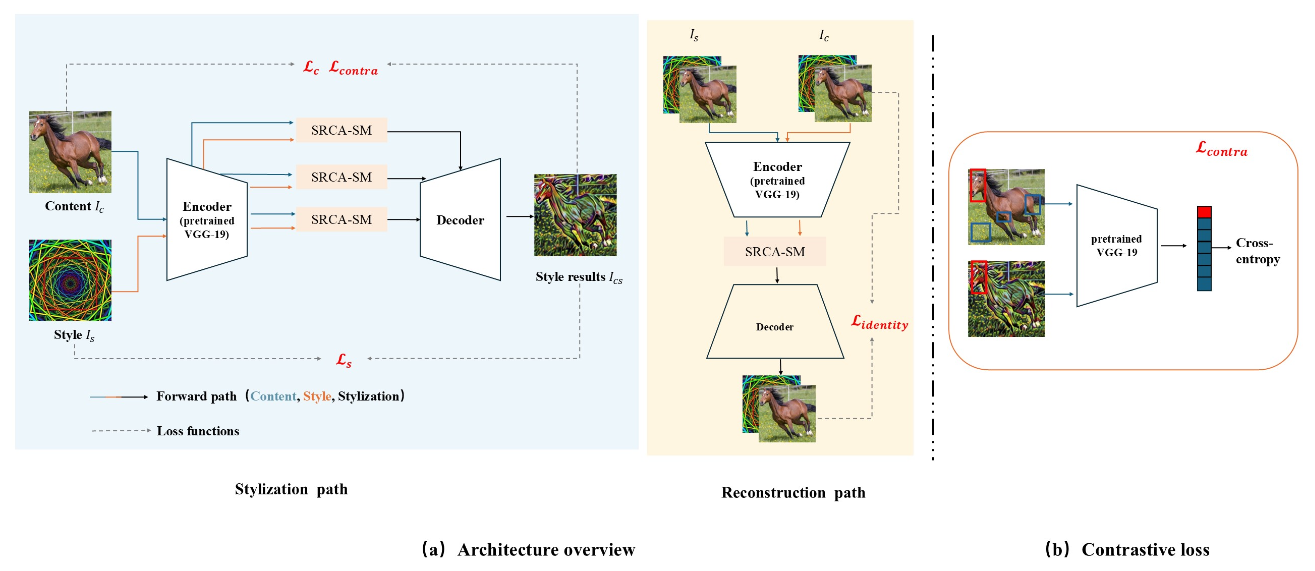 Efficient Hi-Fi Style Transfer via Statistical Attention and ModulationZhirui Fang, Yi Li, Xin Xie, and 2 more authorsIn International Joint Conference on Artificial Intelligence (IJCAI), 2025
Efficient Hi-Fi Style Transfer via Statistical Attention and ModulationZhirui Fang, Yi Li, Xin Xie, and 2 more authorsIn International Joint Conference on Artificial Intelligence (IJCAI), 2025Style transfer is a challenging task in computer vision, aiming to blend the stylistic features of one image with the content of another while preserving the content details. Traditional methods often face challenges in terms of computational efficiency and fine-grained content preservation. In this paper, we propose a novel feature modulation mechanism based on parameterized normalization, where the modulation parameters for content and style features are learned using a dual convolution network (BiConv). These parameters adjust the mean and standard deviation of the features, improving both the stability and quality of the style transfer process. To achieve fast inference, we introduce an efficient acceleration technique by leveraging a row and column weighted attention matrix. In addition, we incorporate a contrastive learning scheme to align the local features of the content and the stylized images, improving the fidelity of the generated output. Experimental results demonstrate that our method significantly improves the inference speed and the quality of style transfer while preserving content details, outperforming existing approaches based on both convolution and diffusion.
- CVPR
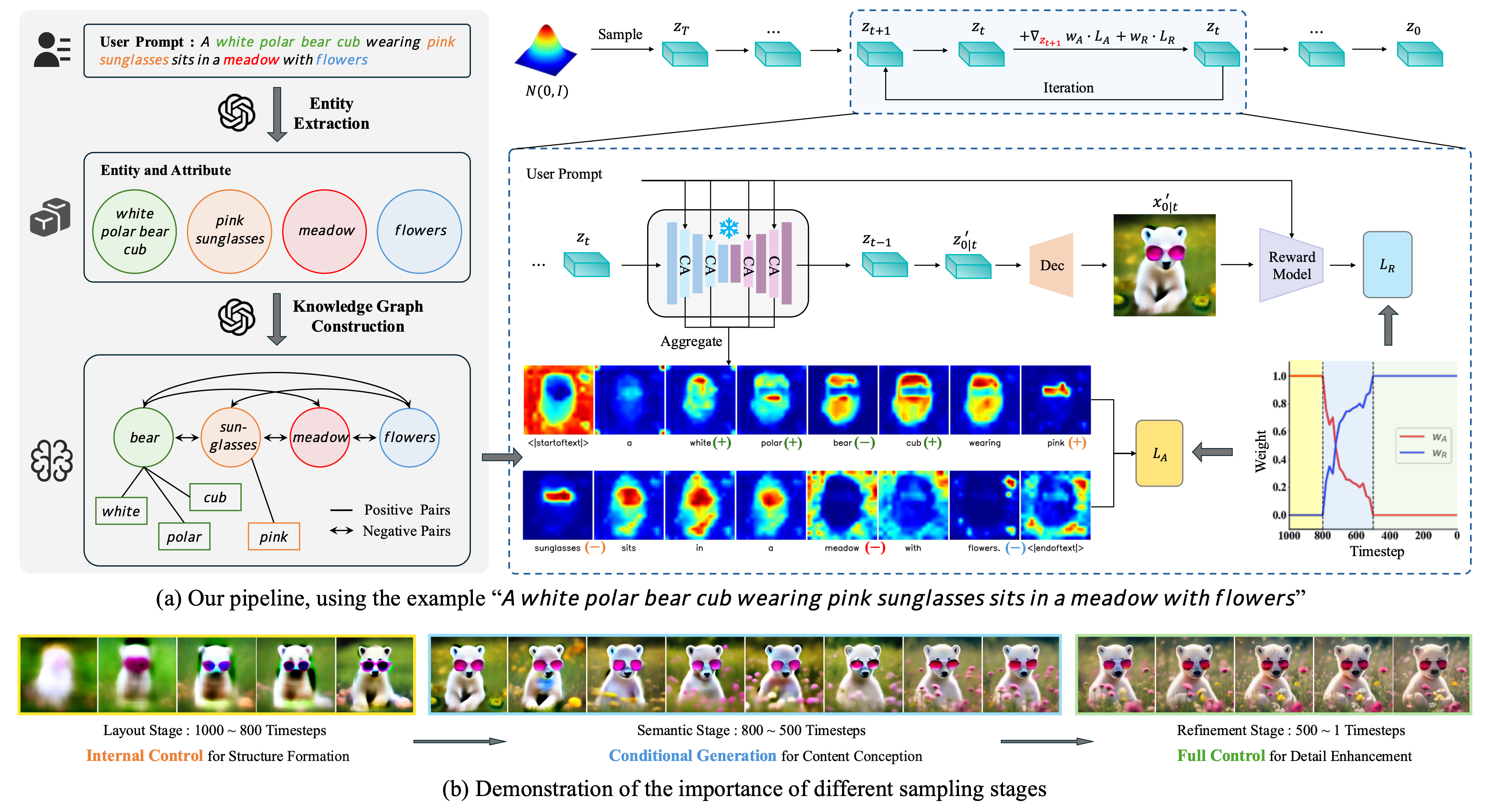 DyMO: Training-Free Diffusion Model Alignment with Dynamic Multi-Objective SchedulingXin Xie, and Dong GongIn IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025
DyMO: Training-Free Diffusion Model Alignment with Dynamic Multi-Objective SchedulingXin Xie, and Dong GongIn IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025Text-to-image diffusion model alignment is critical for improving the alignment between the generated images and human preferences. While training-based methods are constrained by high computational costs and dataset requirements, training-free alignment methods remain underexplored and are often limited by inaccurate guidance. We propose a plug-and-play training-free alignment method, DyMO, for aligning the generated images and human preferences during inference. Apart from text-aware human preference scores, we introduce a semantic alignment objective for enhancing the semantic alignment in the early stages of diffusion, relying on the fact that the attention maps are effective reflections of the semantics in noisy images. We propose dynamic scheduling of multiple objectives and intermediate recurrent steps to reflect the requirements at different steps. Experiments with diverse pre-trained diffusion models and metrics demonstrate the effectiveness and robustness of the proposed method.
- PAKDD
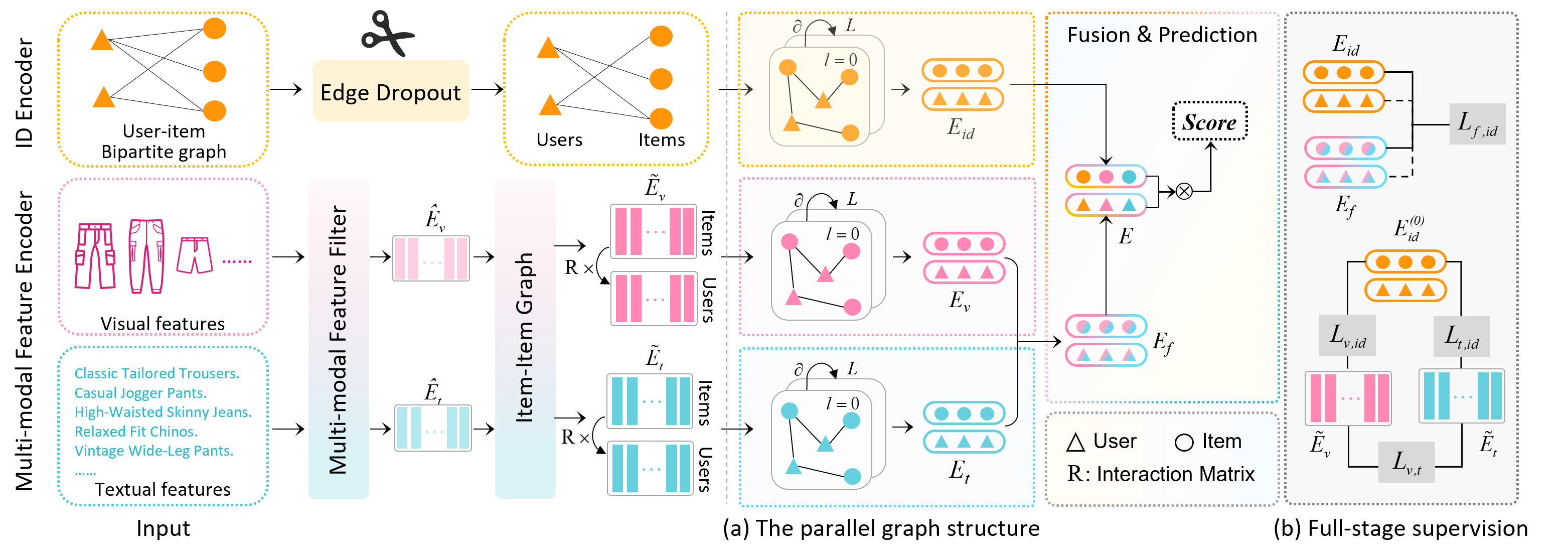 Parallel Graph Convolutional Network for Multi-modal RecommendationWanru Niu, Yi Li, Jianfei Liu, and 3 more authorsIn Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), 2025
Parallel Graph Convolutional Network for Multi-modal RecommendationWanru Niu, Yi Li, Jianfei Liu, and 3 more authorsIn Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), 2025Multi-modal recommendation systems have received significant attention recently. They can enrich ID representations with multi-modal features and achieve better recommendation performance. However, these methods face two limitations: (1) Performing graph convolutional network (GCN) solely on ID embeddings results in the underutilization of multi-modal features; (2) Aligning only the final ID and modality embeddings leads to insufficient supervision for representation learning. To address these challenges, we propose a novel Parallel graph structure framework for multi-modal Recommendation (ParaRec). Specifically, we denoise the input by pruning the user-item interaction graph and filtering modality features, then enhancing items’ modality features. Next, we construct a parallel user-item interaction graph structure to learn and fuse users’ preferences across different modalities. In addition, we propose a full-stage self-supervised learning strategy. It focuses on final ID and modality embeddings and emphasizes intermediate stages of representation learning. Extensive experiments on three real-world datasets demonstrate that ParaRec achieves state-of-the-art results, with up to 11.32 percent improvement in recall 10, compared to the best competitor. Source code availability will be provided upon acceptance.




2024
- ArXiv
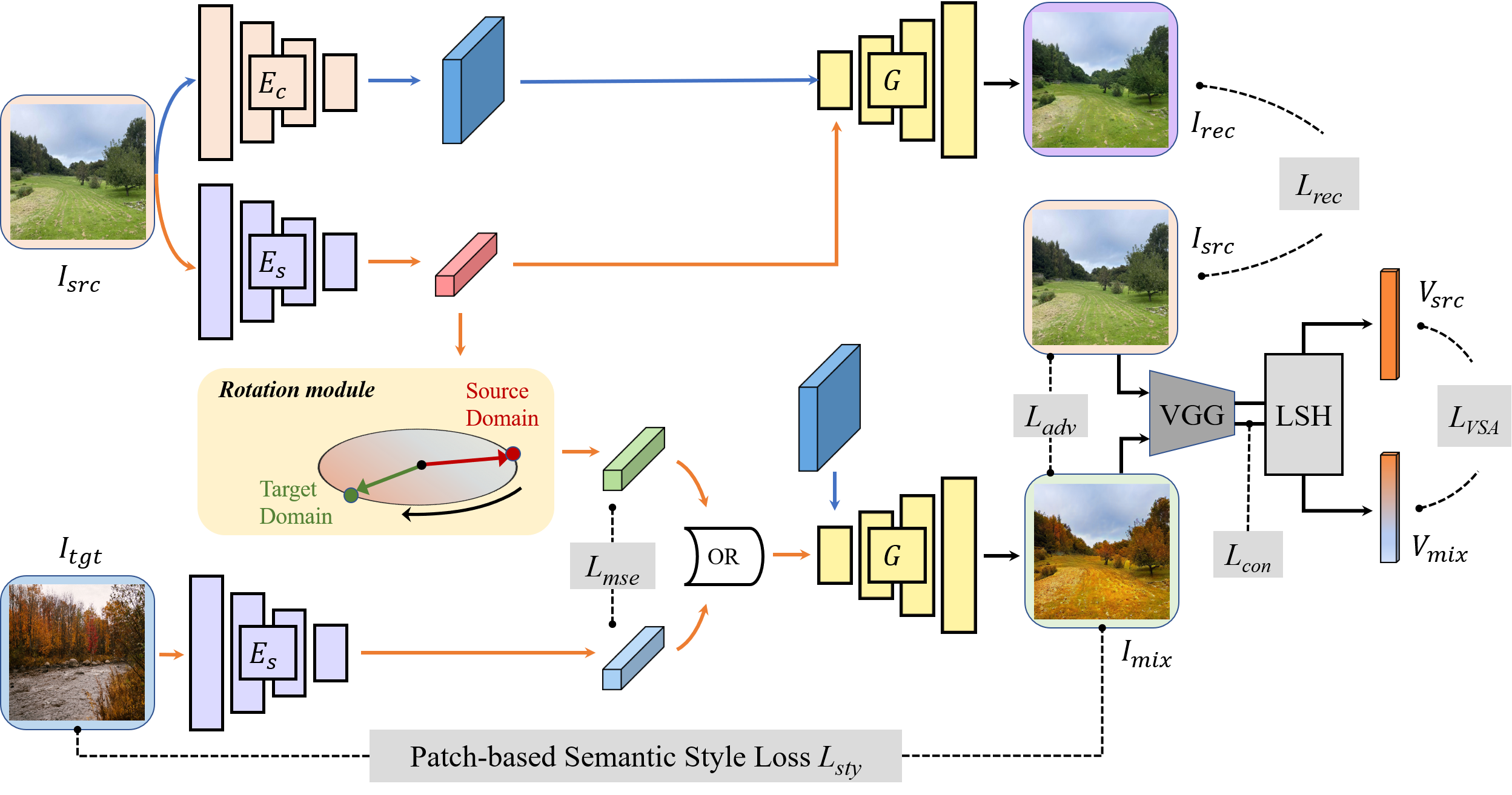 RoNet: Rotation-oriented Continuous Image TranslationYi Li, Xin Xie, Lina Lei, and 3 more authorsIn ArXiv Preprint, 2024
RoNet: Rotation-oriented Continuous Image TranslationYi Li, Xin Xie, Lina Lei, and 3 more authorsIn ArXiv Preprint, 2024The generation of smooth and continuous images between domains has recently drawn much attention in image-to-image (I2I) translation. Linear relationship acts as the basic assumption in most existing approaches, while applied to different aspects including features, models or labels. However, the linear interpolation will sacrifice the magnitude when adding two vectors subject to the sum weights equals to 1 (illustrated in Fig.3). In this paper, we propose a novel rotation-oriented solution and model the continuous generation with an in-plane rotation over the style representation of an image, achieving a network named RoNet. A rotation module is implanted in the generation network to automatically learn the proper plane while disentangling the content and the style of an image. To encourage realistic texture, we also design a patch-based semantic style loss that learns the different styles of the similar object in different domains. We conduct experiments on forest scenes (where the complex texture makes the generation very challenging), faces, streetscapes and the iphone2dslr task. The results validate the superiority of our method in terms of visual quality and continuity.

2023
- ICME
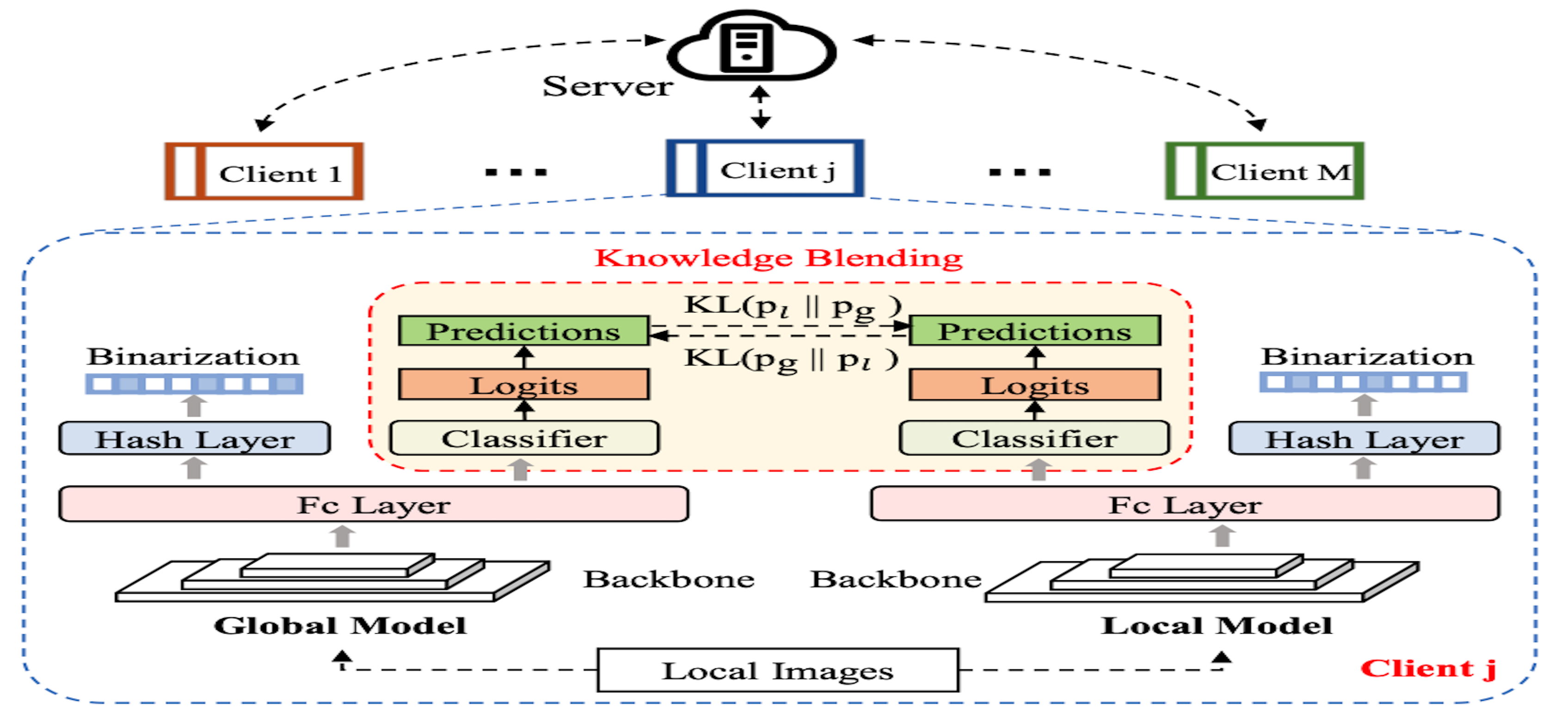 Federating Hashing Networks Adaptively for Privacy-Preserving RetrievalYi Li, Meihua Yu, Xin Xie, and 3 more authorsIn IEEE International Conference on Multimedia and Expo (ICME), 2023
Federating Hashing Networks Adaptively for Privacy-Preserving RetrievalYi Li, Meihua Yu, Xin Xie, and 3 more authorsIn IEEE International Conference on Multimedia and Expo (ICME), 2023With the rise of neural networks, many deep hashing networks have been successfully trained on the basis of large-scale data. However, the conventional learning process has received increasing challenges from the data privacy concerns and the decentralized storage status, especially in sensitive scenarios like surveillance retrieval. Further considering the probable different distributions of the decentralized data, in this paper, we present a collaborative hashing paradigm FedA-Hash (Federating Adapted Hashing nets) to produce personalized hashing models for the participants without exchanging their local data. To this end, the bilateral knowledge is blended gradually during the learning process between the aggregated global model and the local hashing model, instead of replacing the local model with the global model directly. Extensive experiments are conducted on representative hashing networks, involving tasks as image retrieval and person re-identification. The results show that FedA-Hash significantly enables the collaborated performance among different clients.
- ICME
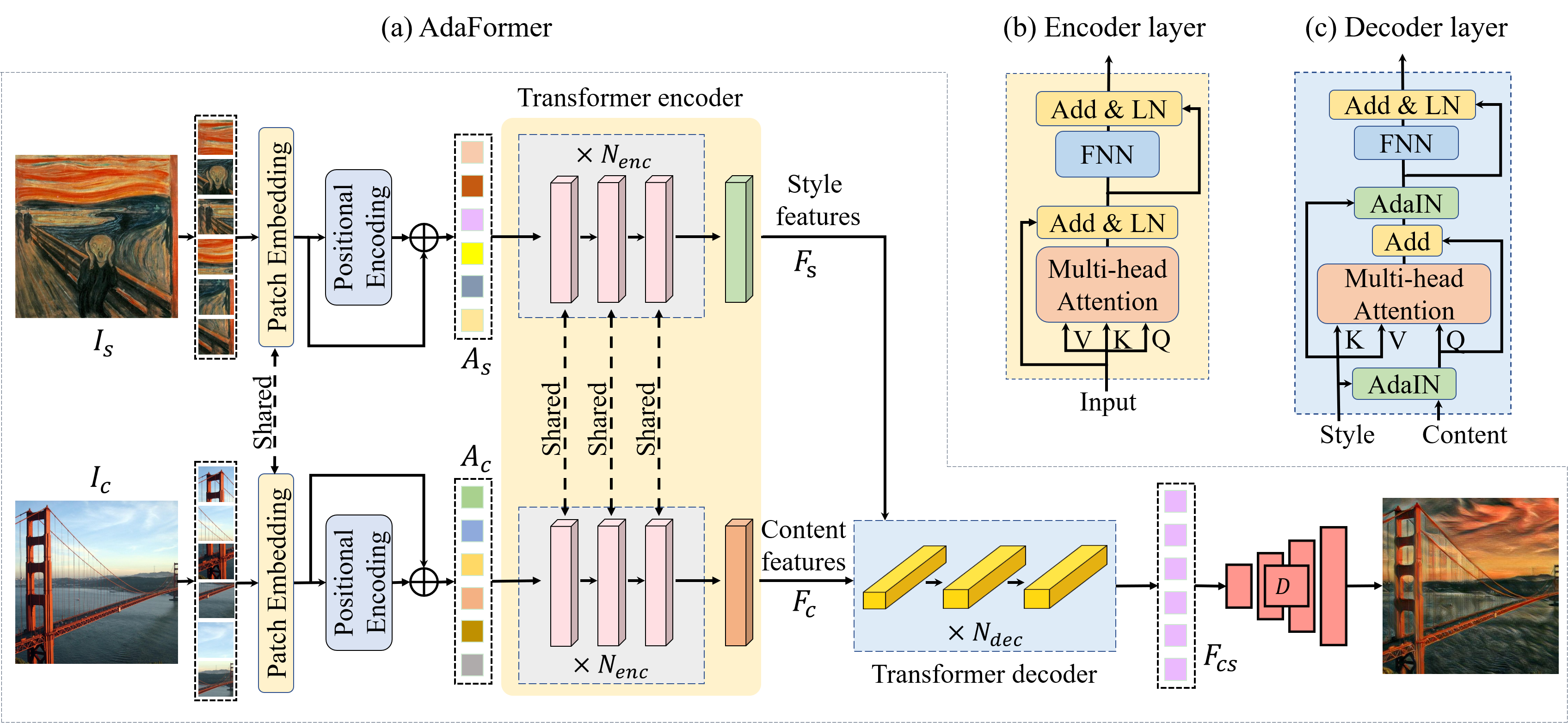 A Compact Transformer for Adaptive Style TransferYi Li, Xin Xie, Haiyan Fu, and 2 more authorsIn IEEE International Conference on Multimedia and Expo (ICME), 2023
A Compact Transformer for Adaptive Style TransferYi Li, Xin Xie, Haiyan Fu, and 2 more authorsIn IEEE International Conference on Multimedia and Expo (ICME), 2023Due to the limitation of spatial receptive field, it is challenging for CNN-based style transfer methods to capture rich and long-range semantic concepts in artworks. Though the transformer provides a fresh solution by considering long-range dependencies, it suffers from the heavy burdens of parameter scale and computation cost especially in vision tasks. In this paper, we design a compact transformer architecture AdaFormer to address the problem. The model scale shrinks about 20% compared to state-of-the-art transformer for style transfer. Furthermore, we explore the adaptive style transfer by letting the content to select the detailed style element automatically and adaptively, which encourages the output to be both appealing and reasonable. We evaluate AdaFormer comprehensively in the experiments and the results have shown the effectiveness and superiority of our approach compared to existing artistic methods. Diverse plausible stylized images are obtained with better content preservation, more convincing style sfumato and lower computation complexity.
- MICCAI
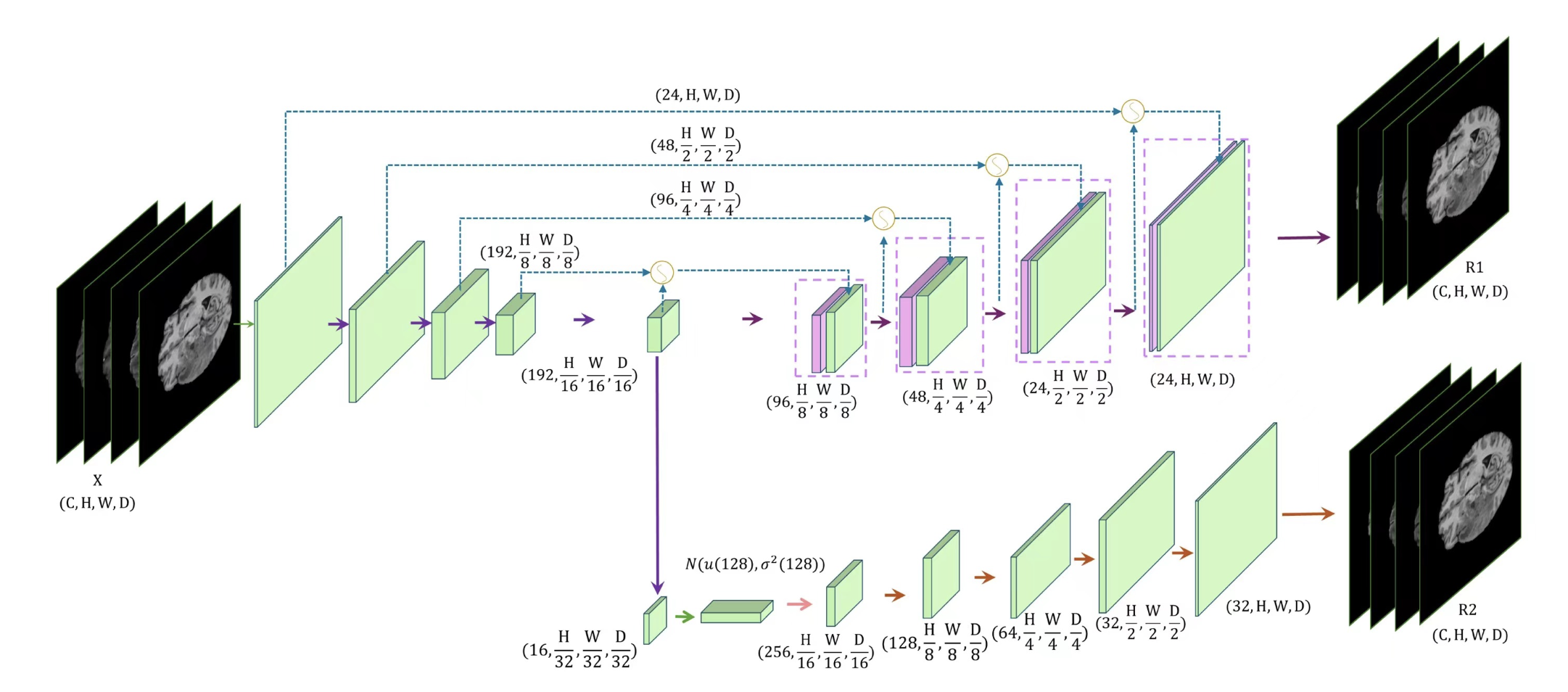 Enhancing Encoder with Attention Gate for Multimodal Brain Tumor SegmentationYi Li, Zhirui Fang, Di Li, and 2 more authorsIn MICCAI BrainLesion workshop (BraTS), 2023
Enhancing Encoder with Attention Gate for Multimodal Brain Tumor SegmentationYi Li, Zhirui Fang, Di Li, and 2 more authorsIn MICCAI BrainLesion workshop (BraTS), 2023Magnetic Resonance Imaging (MRI) is widely applied to diagnose malignant brain tumors like glioblastoma (GBM). Recent deep network based brain tumor segmentation algorithms have facilitated automatic and accurate segmentation on MRI data, benefiting the clinical diagnosis with efficiency. However, existing methods most work on certain datasets but suffer from performance degradation when tested on unseen out-of-sample datasets. In this paper, we integrate the encoder-decoder network structure with attention gate and Variational Autoencoders (VAE) to achieve promising segmentation results across different situations. Considering there are four modalities in each brain MRI sample, an encoder based on 3D convolution is employed to capture the local correlation among both spatial and modal neighbors. Then the extracted volumetric feature maps are fed into a decoder, finally generating the segmentation results with attention gate module. To facilitate better segmentation, we further adopt VAE as an auxiliary decoder to improve the performance of the encoder.



2022
- CVPR
 Artistic Style Discovery with Independent ComponentsXin Xie, Yi Li, Huaibo Huang, and 3 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Artistic Style Discovery with Independent ComponentsXin Xie, Yi Li, Huaibo Huang, and 3 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022Style transfer has been well studied in recent years with excellent performance processed. While existing methods usually choose CNNs as the powerful tool to accomplish superb stylization, less attention was paid to the latent style space. Rare exploration of underlying dimensions results in the poor style controllability and the limited practical application. In this work, we rethink the internal meaning of style features, further proposing a novel unsupervised algorithm for style discovery and achieving personalized manipulation. In particular, we take a closer look into the mechanism of style transfer and obtain different artistic style components from the latent space consisting of different style features. Then fresh styles can be generated by linear combination according to various style components. Experimental results have shown that our approach is superb in 1) restylizing the original output with the diverse artistic styles discovered from the latent space while keeping the content unchanged, and 2) being generic and compatible for various style transfer methods.
